




干NLP的工作干了挺久了,但是对于这么流行的网络却没怎么有记录。。这段时间有空,又听了李宏毅老师的课,感觉十分的清楚明白了,所以在这里做一个学习记录,也供自己以后看
注意:本文假设读者(若有的话)有attention的思想基础和简单的深度学习知识,若没有的话可以由self-attention做一个了解后再单独去学习,在这里不展开attention
1:self-attention怎么来的?
我们看到attention,self-attention一般就会望文生义,感觉self-attention是跟attention差不多用处,只是改变了一些小细节的算法。但是其实不是的,self-attention是用attention的思想改变了RNN的网络,让字之间进行self的attention,这时就可以完全替代RNN来使用,并不是一个简单的attention概念了。
##:2:RNN为什么不够用了?
先放上RNN的构造图:
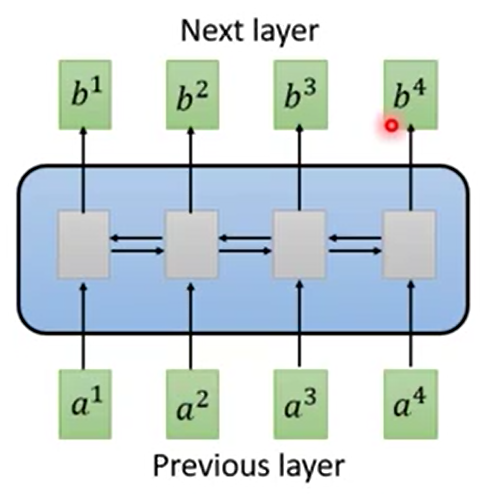
图中明显看出,对于一个RNN序列标注问题,传统的RNN的流程是输入a1后才能得到b1,有了b1后得到a2后才能得到b2,有了b2后得到a3才能得到a3,以此递推的。
这对我们的GPU来说就有一个非常明显的问题,不能并行计算,只能顺序计算。
所以很明显的就有一个现成的思路,就用CNN来代替RNN就可以并行化了。
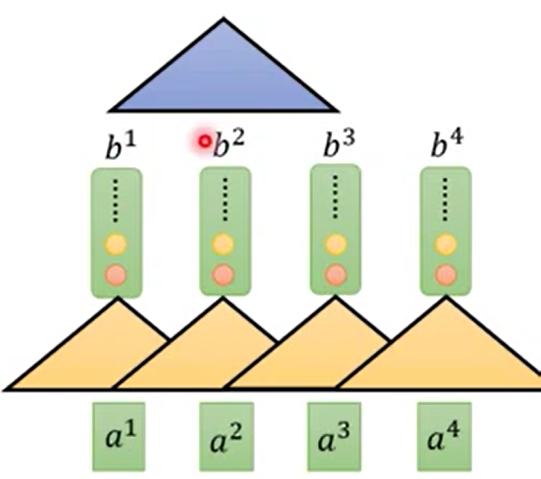
这样每个卷积核都只专注于自己的区域进行卷积计算,所以很简单的就可以进行并行操作让GPU处理。蓝色的部分是弥补黄色区域的每个卷积核只关注过短范围的a的问题,在上层加CNN来考虑更大范围。
虽然用CNN替换后就可以让GPU进行计算了,但是卷积核考虑的范围实在是太小了,这会造成天然的局部依赖问题。所以CNN的方法也只是缓兵之计。
而我们的self-attention就是为了这种情况而出现的。附上论文原文attention is all you need.(https://arxiv.org/abs/1706.03762)是不是都快把预印本的号码背过了hhh
3:self-attention具体细节的计算流程?
首先我们要记忆起来attention的概念,q、k、v分别是什么。
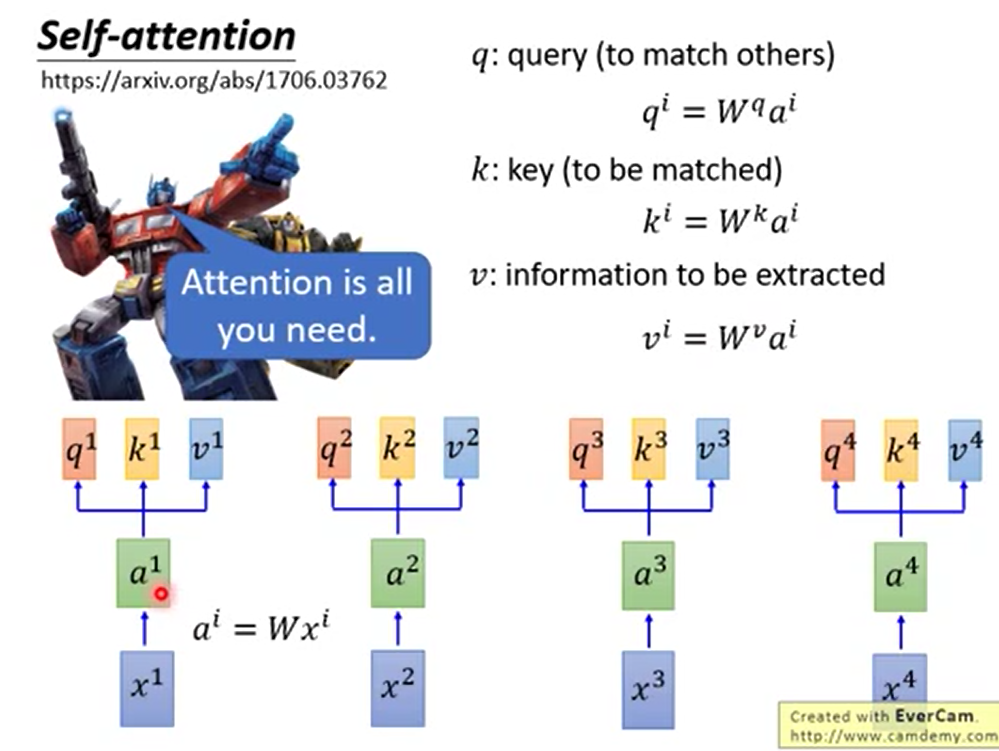
q:query(代表字产生兴趣可能愿意匹配的东西)
k:key(代表字本身对其他的吸引点)
v:information(代表字所内涵的信息的embedding)
我们在这时对每个单个q与所有的k相点乘,得到aj,i。然后做softmax进行归一化。

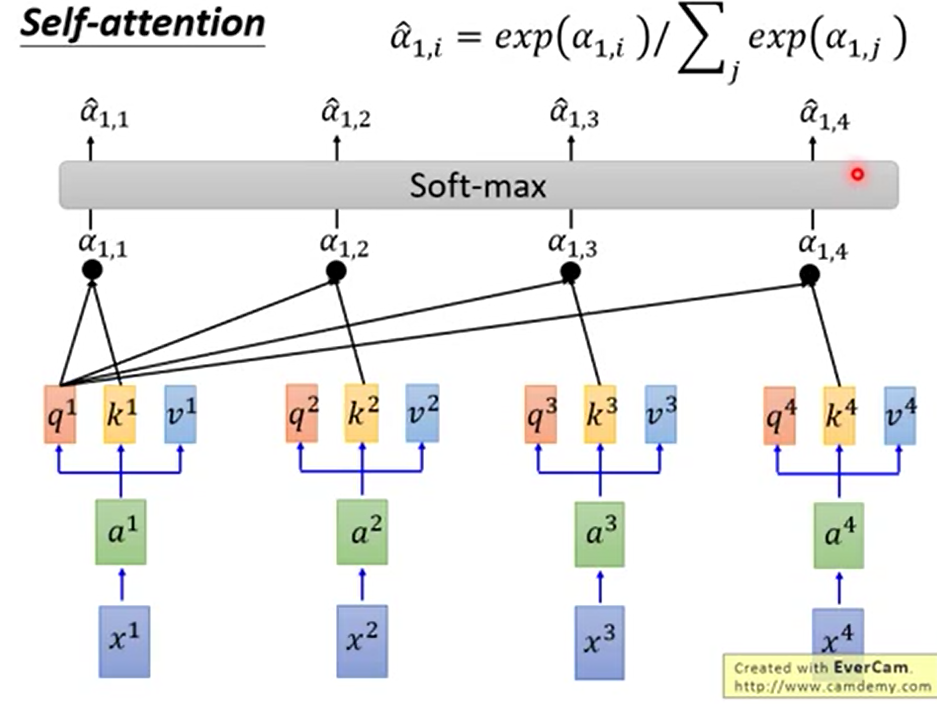
再将归一化后的a作为比例对应乘以每一个v,加和后我们就得到了b
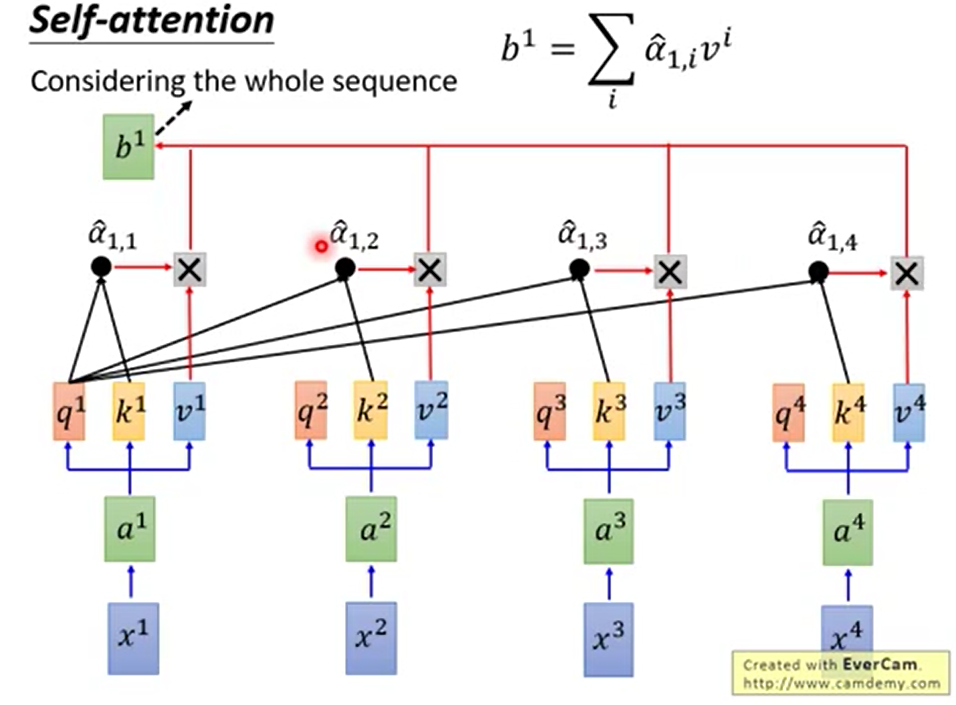
以此类推完成所有的计算操作
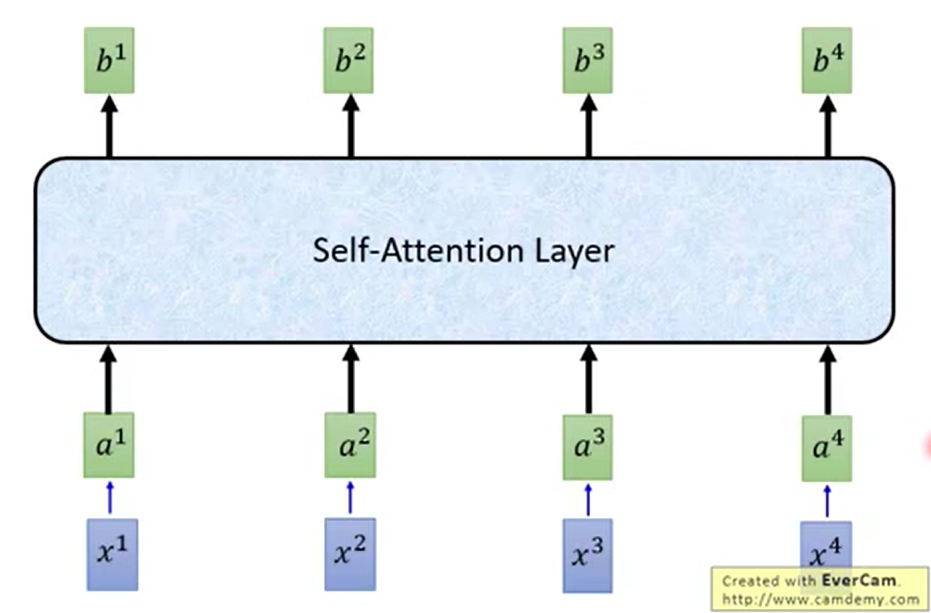
这就是self-attention的计算流程
4:self-attention的优点和缺点?
分析一下self-attention的优点和缺点。
【并行计算,不用全连接可解释性强-字之间产生联系性能强大】
【位置和上下文信息需要额外特殊补充】
优:并行计算
让我们来想一想,self-attention中有什么计算,他们是否都能并行化?(下面的问题可以集中精神思考一下,可以回顾self-attention中所有计算,熟悉后手写)虽然其实就三步计算
首先是输入了a后,对所有的ai乘以Wq,Wk,Wv求到qi、ki、vi。这个可以并行计算吗?
可以
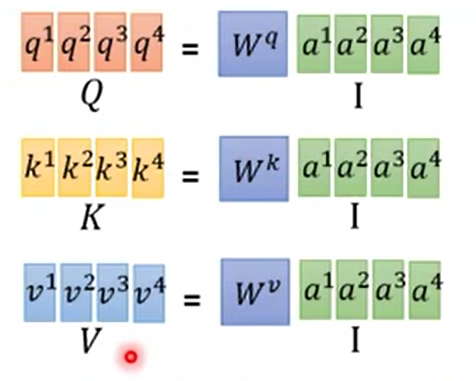
对每个单个的qi对所有的k求点乘,然后softmax求到匹配程度,这个可以并行计算吗?
可以。
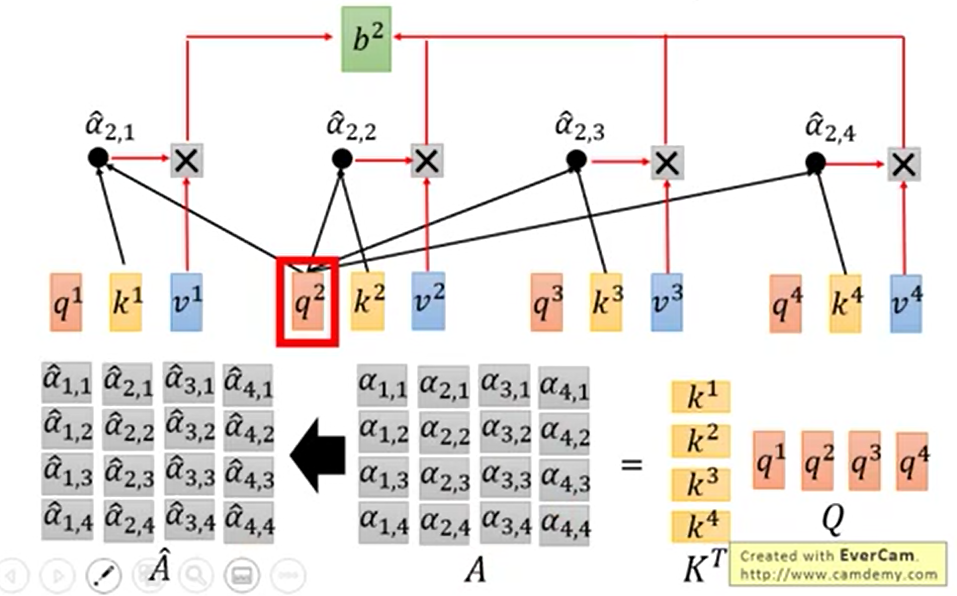
由获得的A矩阵乘以所有的信息v,得到b。可以并行计算吗
如果你动脑想了的话这时应该在脑子里都有了计算的样子了。A在右边的,当然可以
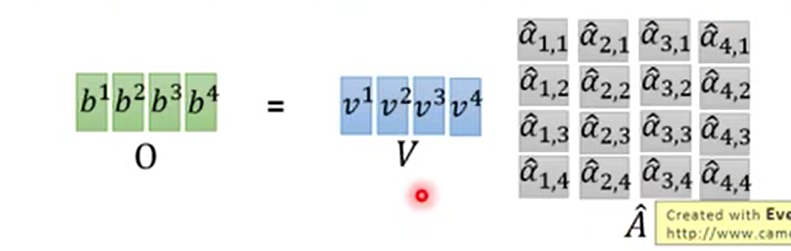
我们最后来回顾一下所有的三步计算。
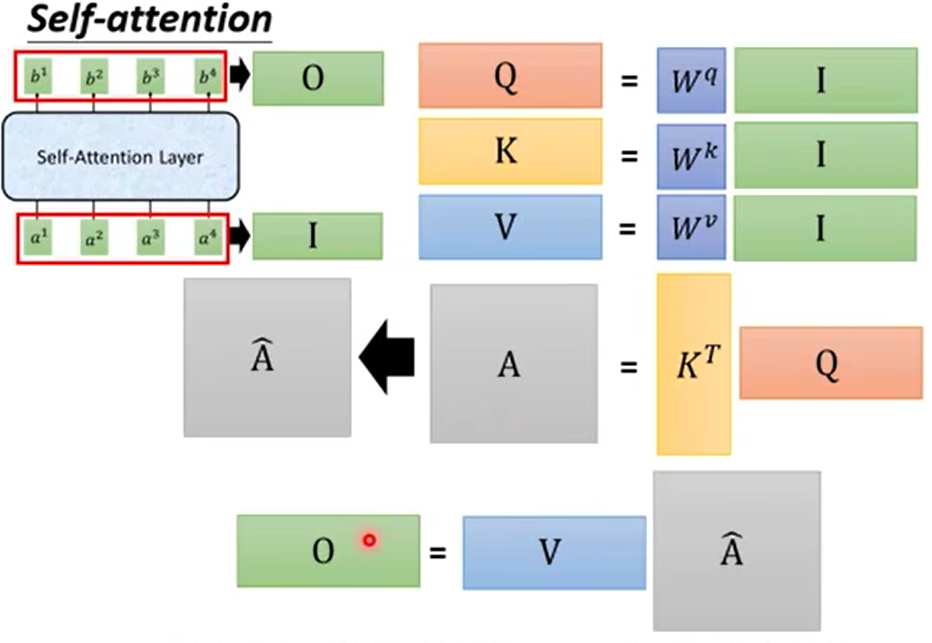
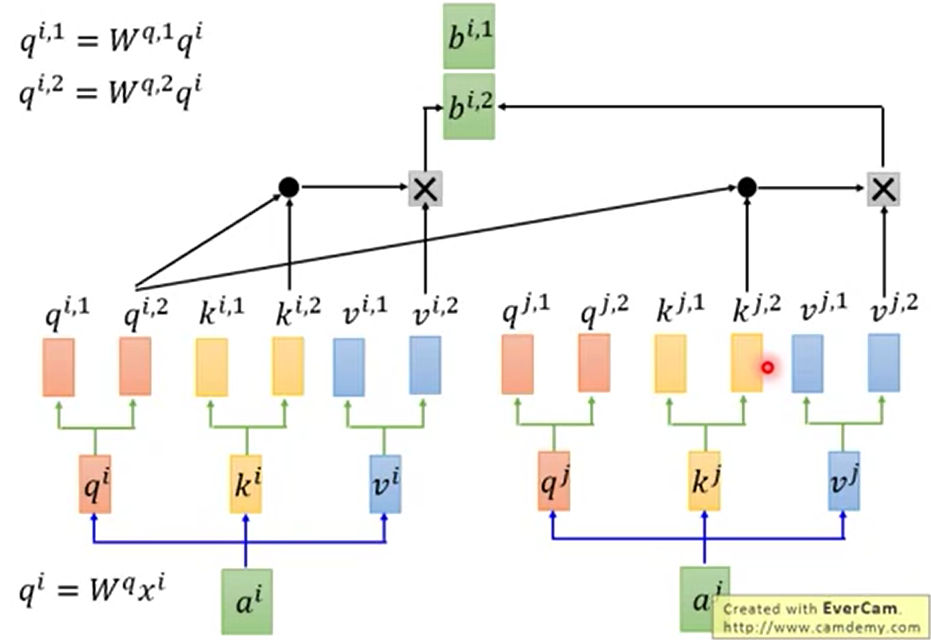
而现在流行的多头self-attention概念也只不过是多了几个qkv,多了几个中间过程的a最后多个几个b。
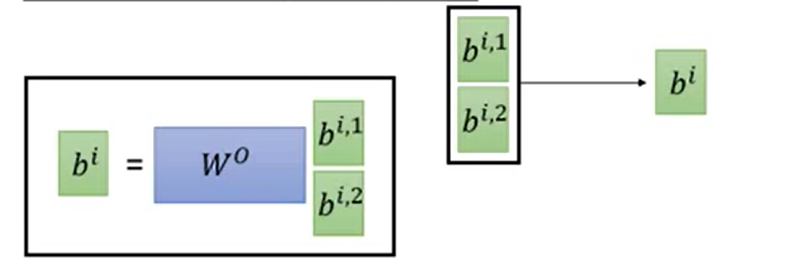
最后将多的几个b组合在一起乘以一个矩阵进行降维。合成一个b
这就是self-attention的显著特点,并行化的证明和具体流程了
优:可解释性强,性能强大
可解释性强,是因为self-attention其中的各个参数所代表的含义十分的明确,比较容易从数学的角度来理解和可视化。得到的结果也可以很容易的明白到底产出了什么,不像CNN那样很抽象的。
举例:
9%25QHN35Q8KMU7-82b594349ba743d9a22c18acb9a67e66.png)

↑只改变了最后一个词
性能强大则即有直觉上的合适,也有现实的依据。,
直觉上的合适,是说没有太明显的小范围依赖和长距离稀疏。用统一的embedding来给模型提取qkv信息,中间潜力大也可以迁移学习。比RNN高出不知道多少了。。应该比LSTM还好上一些
现实的依据,就是self-attention构成的transformer性能强大,transformer构成的BERT是最流行也是目前最广泛的功能最强大的NLP模型之一。
缺:无位置编码
老生常谈了。。transformer里要手动添加位置编码,BERT也是。这里不细节展开。只说一下可以绝对位置编码,相对位置编码,添加上下文信息。
5:transformer
transformer则是基于self-attention提出来的一个整套模型。其实给我的感觉就是self-attention和一些配件的组合。
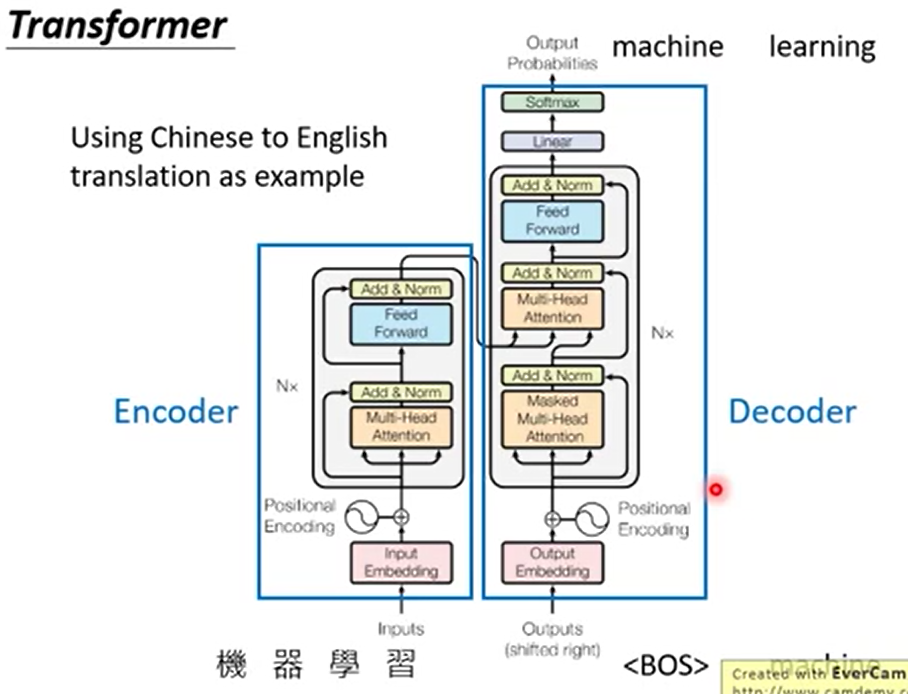
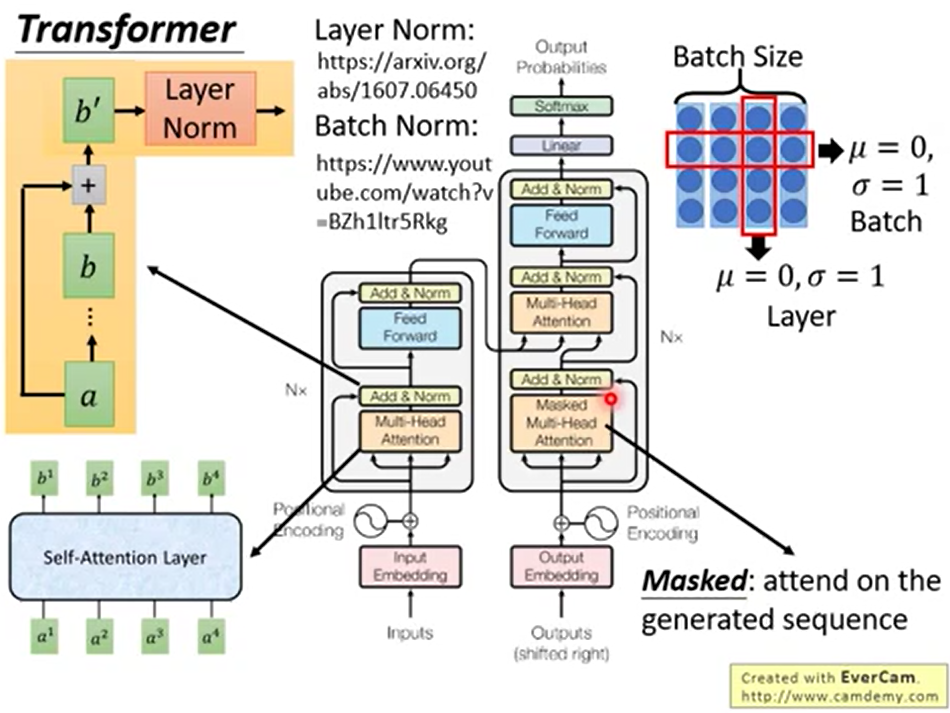
左边是encoder,左下角做了input并embedding后添加位置编码。到多头attention由a得到b,做a+b并layer normlization后到feed forward里改变形状,重复N次后[框外面]输入到decoder里。
decoder也是这么来的。
但是我们发现在decoder中第一个的masked是个啥意思?

这里的mask若是对transformer整个过程理解不够的话会造成一些困扰和猜测,难道是跟BERT一样随机mask一些单词便于机器阅读理解?其实不是的
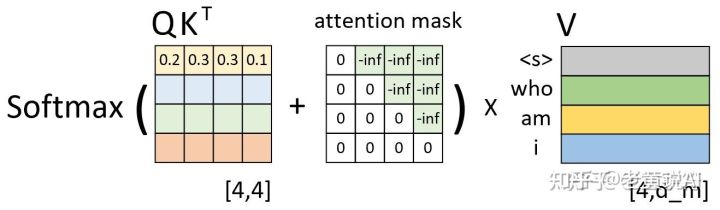
之所以做mask操作,是因为我们在训练transformer的时候得知了所有正确的输入和输出,是可以进行并行操作的。但是transformer在预测的时候还是得一个一个出输出结果哇。。这就不能并行计算了,还是要一个一个给输入和输出的。若我们在训练时不给“理应未知”的Q,K信息以mask,那么训练与预测的不同会让模型效果大幅下降
那怎么mask呢?就乘以一个全是负无穷的上三角矩就可以啦~
6:CNN,RNN和trans三个信息提取器在NLP领域的比较
既然要在特指的NLP领域进行比较,那不如先来总结一下NLP领域的主要的基础任务有那些,以便在特定的任务中对他们的性能进行比较
- 序列标注任务(NER,分词,语义标注)
- 分类任务(情感分析,文本分类)
- 关系判断(NRE,对话系统,机器阅读理解)
- 生成任务(文本摘要,机器翻译)
主要注意的是各个任务并不是完全独立的。任务之间有很多共同点,甚至任务之间会互相配合来完成某一或某些任务。在这里做区分只是因为这些任务的计算方式有比较大的区别,以便于比较不同信息提取器的区分。
RNN在NLP中怎么用?
改编成LSTM和GRU的RNN还算是RNN吗。。我个人来看应该是不算的。
所以RNN其实用法就不多了,大多都是与其他模型组合在一块吧。要魔改也就是给隐层之间和输出之间做一个连接,变的有一定程度的并行计算能力。其他的也没什么好说的,所以这里直接跳过吧
CNN在NLP中怎么用?
其中CNN是可以用各种trick来让自己更适合解决NLP问题的。
1:比如Dilated CNN。
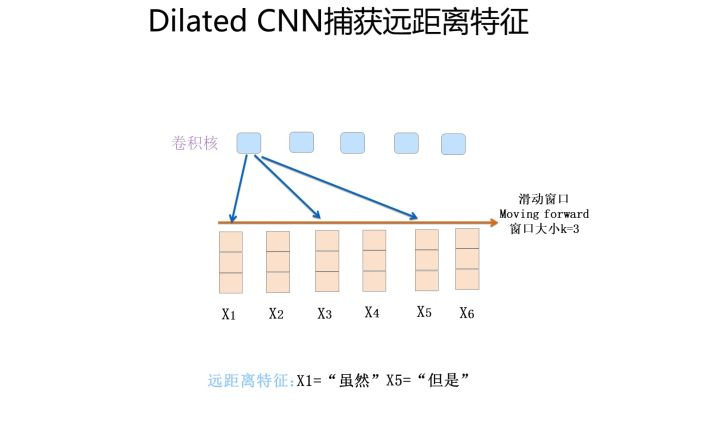
一个卷积核只能有三个输入,却想覆盖更广的范围。那么就跳着收集信息。。图中收取了1,3,5的信息。看起来有点点不靠谱但是其实真的很管用。能在大部分场景下有用的!
2:比如加深CNN网络
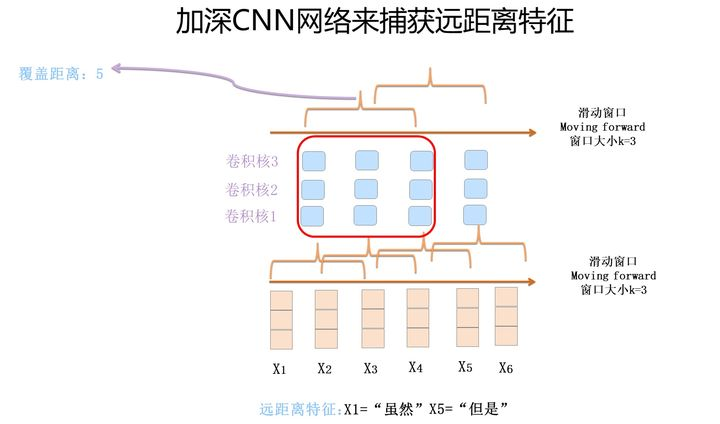
这个方法前面好像说了?有好处有缺点把也是。。也是一个解决的方法
现在主流的CNN用法是下图这样的
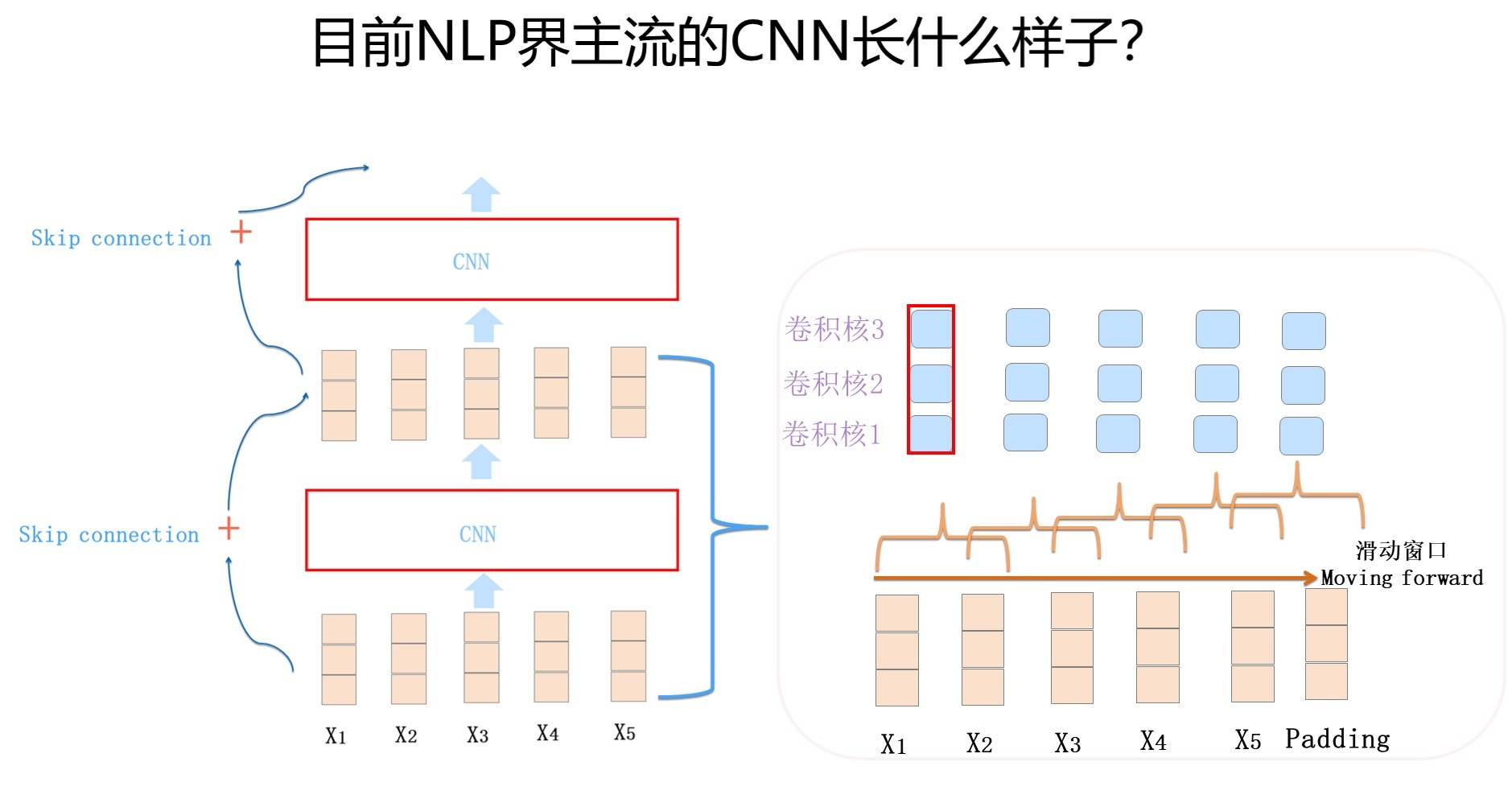
用了Dilated CNN,Skip connection等操作来优化。这就是CNN在NLP领域做出的一些改变。
需要了解的是若用的相对位置,别做pooling。。。那点脆弱的信息经不起溺水。。
transformer在NLP中怎么样?
而我们用transformer时也不是直接用我们上面给出的模型图,而是把模型图看作是一种transformer block来使用。
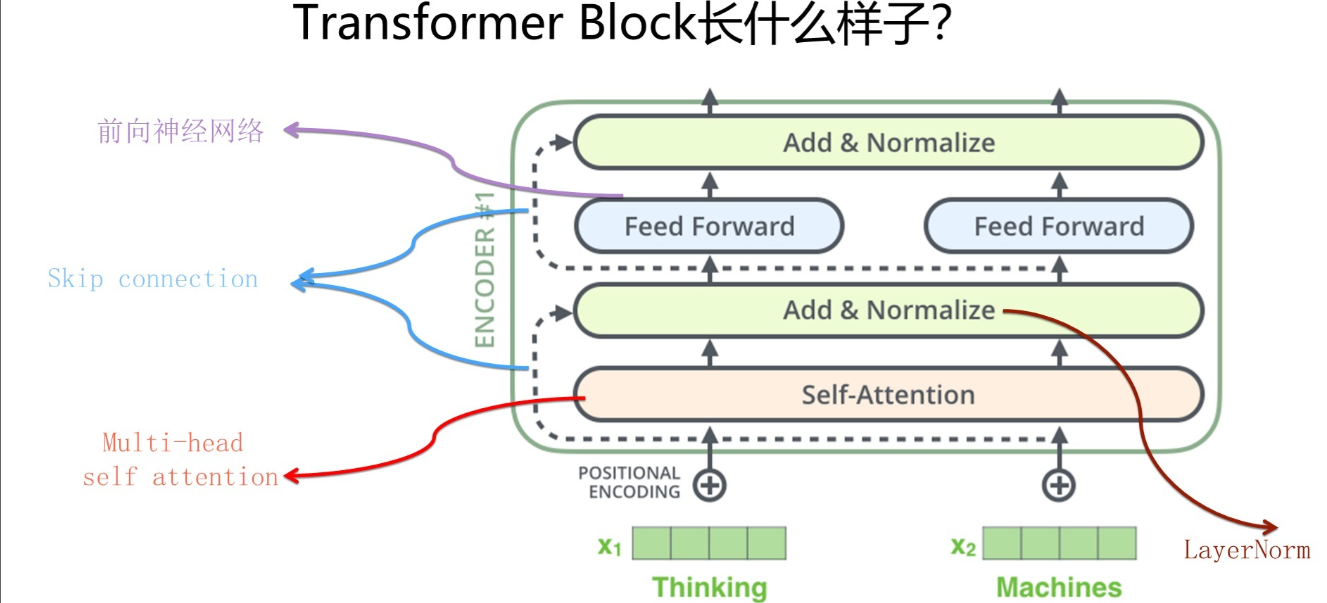
其实encoder,decoder都是这么一块。只不过是decoder在训练时要mask未应知道的信息而已,本质上也是一样的transformer block。
单纯用transformer的模型大体有两个版本,transformer base和transformer big。base就是有12个transformer block,big就是有24个。big就是一个相对比较大的模型了,
三剑客具体能力比较?
以下的数据来自论文《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》。这里只是对论文的实验结果进行表述,自己其实也没做实验。。
那么接下来我们从四个角度对三剑客的能力进行比较:
- 语义特征提取能力
- 长距离关系特征捕获能力
- 任务综合特征抽取能力
- 并行计算和计算效率
1:在语义特征提取能力上:
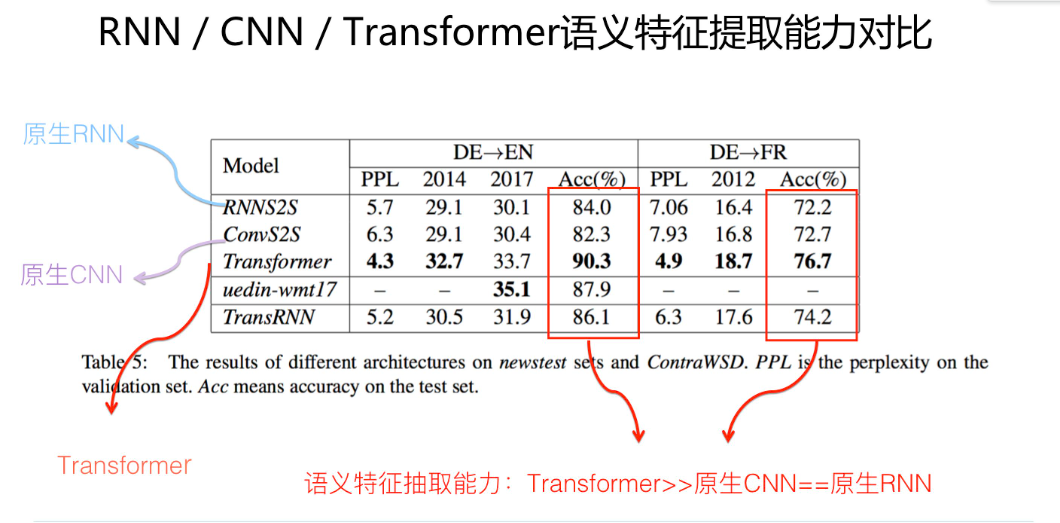
出乎意料的是CNN没有RNN能力强大。但是二者离transformer都有一定的差距。
2:在长距离关系特征捕获能力上:
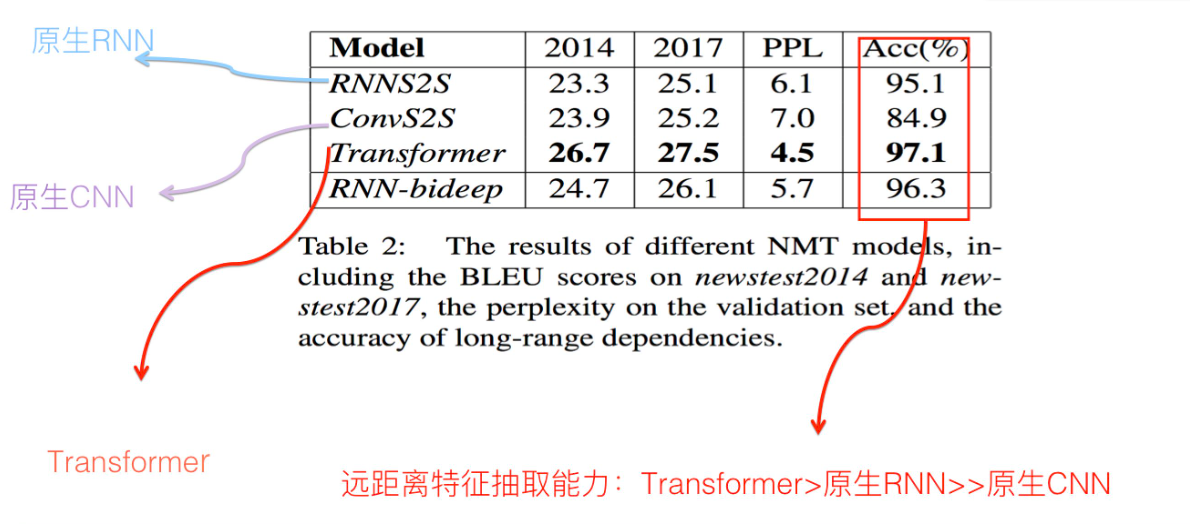
这方面是比较符合直觉的。CNN最弱离RNN和transformer都有很大差距。transformer比RNN也好上很多。
需要注意的一点是,transformer的muti-head数会极大的影响长距离的关系特征捕获能力。还是要多一点好。。
3:在任务综合特征抽取能力上:
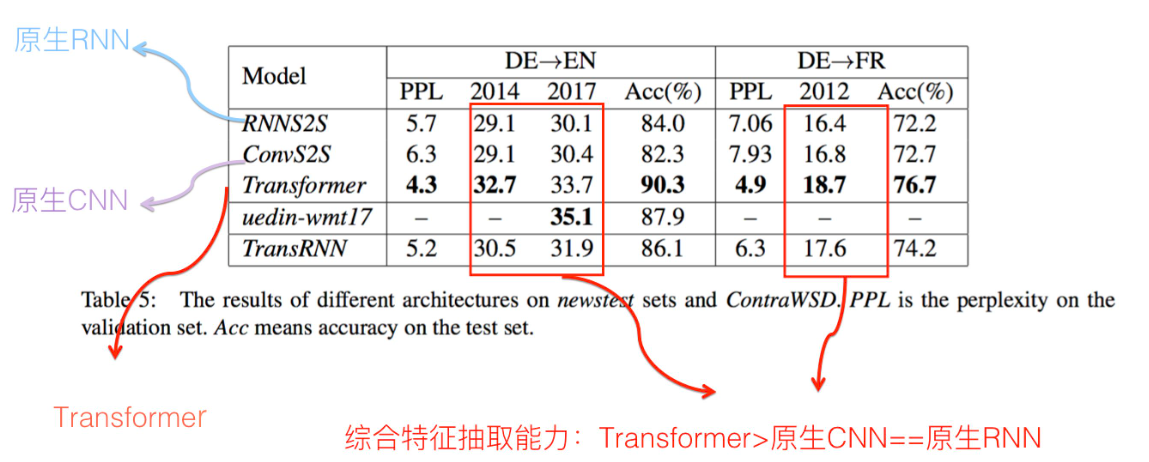
也是比较符合直觉的
4:在并行计算和计算效率上:

目前常用的embedding size大体从128到512,句子长度根据任务有所不同有长有短。但是self-attention组合成transformer计算量就大了。。所以排名应该是Transformer>CNN>RNN。但是因为Transformer和CNN并行计算能力太强。。所以实际训练花费时间反而是RNN>CNN>Transformer。下面给出一些论文的证据:
论文“Convolutional Sequence to Sequence Learning”比较了ConvS2S与RNN的计算效率, 证明了跟RNN相比,CNN明显速度具有优势,在训练和在线推理方面,CNN比RNN快9.3倍到21倍。论文“Dissecting Contextual Word Embeddings: Architecture and Representation”提到了Transformer和CNN训练速度比双向LSTM快3到5倍。论文“The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation”给出了RNN/CNN/Transformer速度对比实验,结论是:Transformer Base速度最快;CNN速度次之,但是比Transformer Base比慢了将近一倍;Transformer Big速度再次,主要因为它的参数量最大,而吊在车尾最慢的是RNN结构。
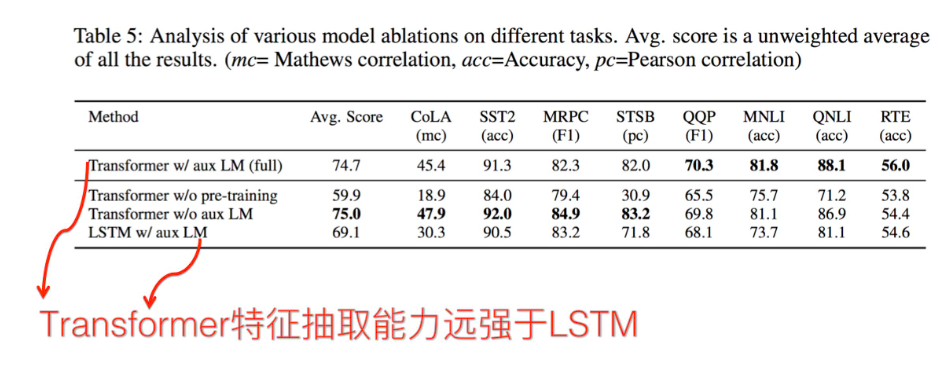
一个十分有趣的方法。
这里有个十分有趣的方法。若将Transformer中self-attention替换成RNN或者CNN,他们的效果会怎么样
就像这样!
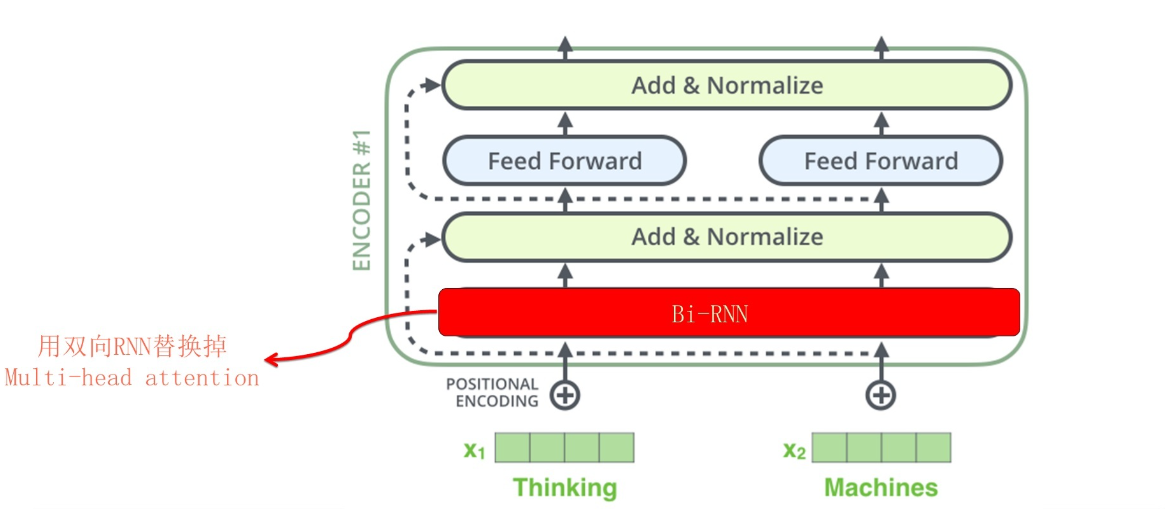
实际测试的效果如何呢?以下结论来自论文《How Much Attention Do You Need?A Granular Analysis of Neural Machine Translation Architectures》
对于RNN替换到tranformer里的情况:
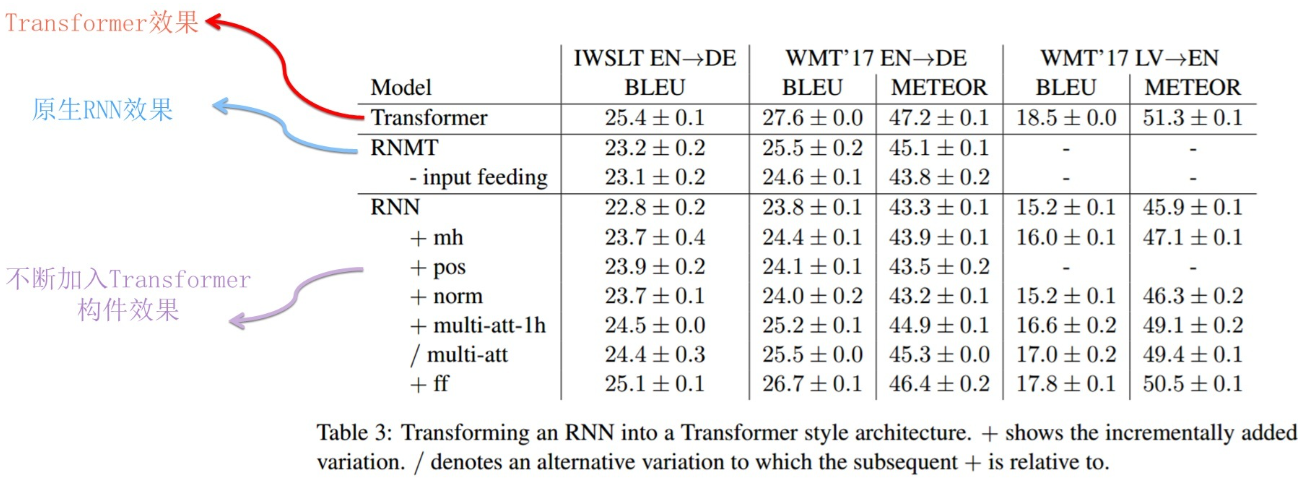
可以看到虽然与原生Transformer仍然有差距,但是确实在不断的靠近。一些指标甚至已经十分的相近。
对于CNN替换到Transformer的情况:
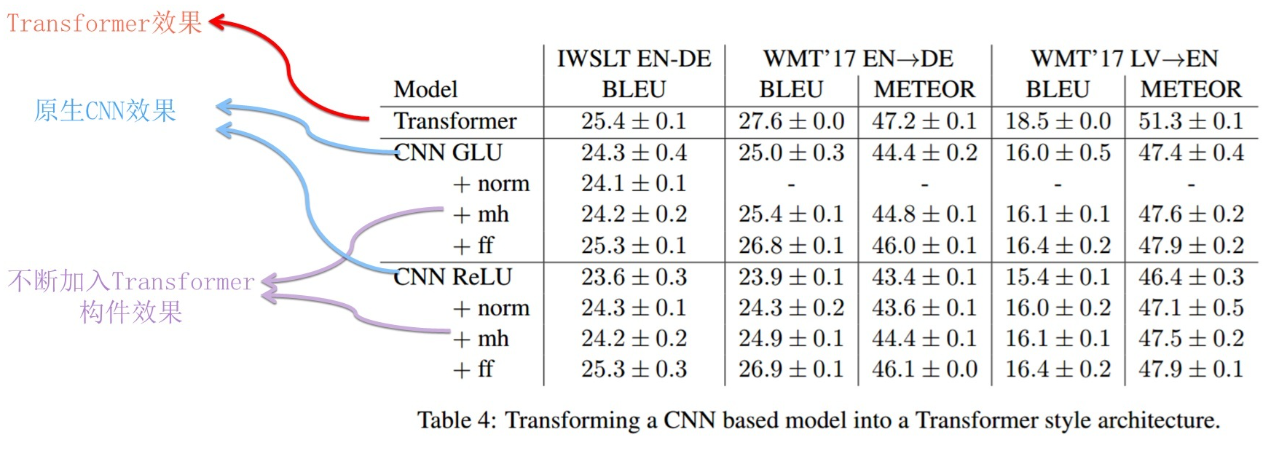
这个差距就有点大了。不过这也符合直觉,CNN本身也就一般,提取方式不对
所以这就证明了Transformer之所以好,也不全是self-attention的功劳。也是有encoder,decoder,layer norm,跨层连接加和这些组件的功劳的。不能把transformer厉害的原因都归在self-attention上。但是self-attention也确实比单独的CNN,RNN要更厉害。最厉害的是他完成了并行计算,就可以堆更大的网络,加入到更多网络的里发挥作用,也就有更好的性能。这其实在另一个角度上也是解决了AI的问题hhh
Q.E.D.

){kind=link}
Comments | 0 条评论