




项目和问题简介
本来想要先介绍问题的,但是想到不在一个具体的问题下讨论问题一点都不直观。所以决定先先介绍我在公司做的两个项目面对的大体问题:
项目一:连续文本切分的任务
任务介绍
| 原文 | 作者 | 文献题名 | 文献出处 | 语种 | 母体出处 | 母体出版年 | 母体出版卷 | 母体出版期 | 母体出版页 | 母体出版地 | 母体出版社 | 版次说明 | 学位论文授予单位 | 待发表 | 会议地点 | 主编 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [10] Liu Zhiyang, Gao Yan, Shao Shanshan, Implement the National Standardization Strategy to Promote the"Going Out"of China's Standards[J]. Mechanical Industry Standardization and Quality,2017,36-40(In Chinese) | Liu Zhiyang, Gao Yan, Shao Shanshan | Implement the National Standardization Strategy to Promote the"Going Out"of China's Standards[J] | Mechanical Industry Standardization and Quality | (In Chinese) | 2017 | 36-40 |
(其实自己手动输入了两条数据,让人更能体会数据的差异性,但是加入了另一条不知道为什么进度条就划不动了,所以还是只保留一条数据,大家参考一下就行)
直观思考:正则表达式分类
可能很多人看到这条数据首先想,这个直接用正则表达式不就能做吗? 我公司一开始也是这么想的,一开始跟我说了总之做不好。后来问了之前做这方面的人。
他说他们想尽办法写正则,总是这边对了那边错,做了这个引文分割的正则有20年,加了过滤条件(估计过滤了不少)平均正确率也只是80%(不是全对率,是每个的正确率),根本用不了。
后面想了一个办法,是能分出来多少算多少,分出来要用的时候往回匹配那些人工分好的引文看看有没有一样的,属于摆烂了。。本质上没创造更多的引文分割项,也不能就此缩减人员减少压力,只是完成了任务。
初步思考:NER命名实体识别任务
所以我的任务就是换用深度学习机器学习的方法,看看怎么能做的更好。
我拿到这个任务后,给这个任务第一个建模就是ner命名实体识别,具体进行建模的方法就是
1: 直接拿字段往原文里匹配,匹配到完全一样的一起进行bert的编码后存起来后面标上对应的标签。
2: 字段里有原文里没有的先删去所有符号只匹配字母,若字母能对的上就根据原文符号的补全,若字母对不上的算是错误数据。
3: 原文里有字段里没有的算是label:0无意义。
然后直接放到一个标准模型CNN+BiGRU+CRF里进行训练,经过一系列细节的优化后得到准确率如下
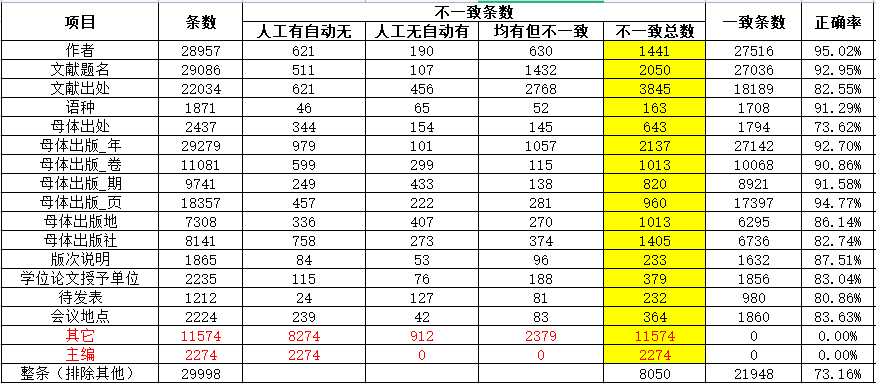
看起来不错对不对?但是对于各个小项的准确率都不是特别高,到时候别人用的时候再加过滤条件很麻烦。而且会出现很多匪夷所思的错误。。比如:标题是研究1973年中国的经济,那这个1973就被分到了母体出版年的字段里。因为做ner是按照token来进行classfication的。没有大块的概念
所以下面要做的自然而然就是先给字段分块,再把分好的块做文本分类。这样的思路至少不会出现很离谱的错误,就算出错了也能及时看出来并且弥补。在一定程度上应该能把这个73%的全对率再提升一下
然后就是分两块,一块是分大块,一块是文本分类。
分大块就是预测每两个块之间的标点符号有没有把块分割开,只预测标点符号。实际上这个也是ner的思路。最后结果平均准确率99.5%,全对率88.5%。算是能接受的程度,分错的都是一些比较明显的,要么是括号,要么是中间有空格没分开。到时候用正则判断一下就能过滤。
文本分类
过滤掉的咱们就不考虑了,重点是怎么把过滤过的,分好块的用文本分类全分对?
一开始把每条数据的字段与别的数据的字段直接连接起来,直接按照打乱的字段(batch,1,hidden)、而不是按照每条的所有字段(batch,每条的字段,hidden)输入到网络里。得到的结果还挺能接受的整体正确率90%。但是全对率比较低只有3%。但是测试时结果还是能接受的所以没管。。。
后面测试时发现出错的地方基本都是,对结构不了解。比如为了保证平均准确率,对单条进行保守性的预测。保证平均准确率90%以上,但也不往上升了。导致整体准确率很差,而他也没想过提高 整体准确率。
因为分析出了问题所在,没有结构性的信息,自然而然的想去给模型提供一个整体的结构信息,所以改进方法是按照整条输入网络训练,不知道为什么反而整体准确率掉到了73%。。我一开始推导了几遍公式都感觉不太应该
单个字段的数据矩阵shape是(batch,1,hidden),整条的数据矩阵是(batch,seq_len,hidden)
两个方法模型上唯一的不同就是整条输入的bert分别对输入的非空字段编码后stack到一起输入到fc网络层
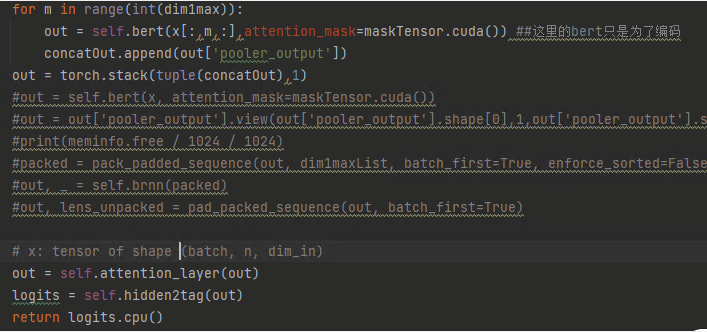
那么是为什么呢?你能知道为什么吗?可以思考一下再向下看来揭晓答案。这个地方是这个项目里目前给我印象最深刻的地方
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
(想好在看哦)
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
↑↑↑↑↑↑↑↑↑↑↑↑↑
答案分析如下:
bert在打乱字段直接接fc层跑回去的第一个epoch的整体准确率是87.9%,全对率1%。在整体输入到fc层跑回去的第一个epoch的整体准确率是73%,全对率25%。整体输入到lstm层跑回去的第一个epoch的整体准确率是62%,而且训练了16个epoch基本没变。加上了自注意力后的第一个epoch的准确率81.9%,全对率33%。。但是上升的比较快。打乱字段的batch是40,整体输入的batch是6:分析原因如下:
分析原因:
1:loss不好学了
首先肯定上面添加整体信息这样的思路是没问题的,是要给一个整体的信息,打乱的输入肯定会导致最后比较像的切割的混乱。但是为什么平均的正确率反而低了呢?当这样不合理的事情发生时首先考虑loss的学习过程,loss怎么算的,学了什么,回到哪里怎么回去的会发生什么变化。
之前单个字段输入训练时算loss学习的是怎么分对单个的,现在整条输入训练时算loss学习的是怎么分对所有的,把(batch_num,6)的loss一起算了。而之前的loss的shape是(batch_num,1)。最后loss只不过是一个数值,依次回到各个网络罢了,所以这里loss训练传播的肯定就慢。
2:数据少了
之前打乱时数据量是(所有条*他们有的字段数),训练一次不仅loss好学,数据量还多。整体输入训练时数据量是(所有条),训练一次loss比较难学,数据还少。所以考虑基础数据量和任务变化的话应该整体输入跑6个epoch,才顶打乱的一个epoch
3:不仅提供了结构信息,还把训练的根本任务改变了
那个算平均准确率的,其实本质上是在比单个字段的准确率。而算全对率的,其实本质上就是是在比整条的准确率。
而相对应的是单个字段输入训练,平均准确率高,全对率不高是正常的。整条输入的训练,平均准确率一上来不高,全对率高也是正常的。
能理解吗?你想的是,现在整条一起输入进行训练,可以获得到整条的结构信息。而fc层同时矩阵乘多少个seq_len都是一样的,本质上都是同样参数的fc层矩阵乘以不同数量的seq_len的hidden_nums的矩阵罢了。所以fc层一样,又有了结构信息,bert编码也没差别,整体输入训练的结果一定比单条的更好吧?
实际上不然。你忘了考虑loss也更难跑了,而且因为训练的目的是一起出来的所有字段,所以loss要求的是整体字段的准确率高,这样训练的任务变得更难了,要控制一起出来的所有字段全对,而不是不考虑整体只考虑单个了。任务更难,一开始的准确率也就自然不高了
这就是原因。解释清楚了是不是就觉得很合理了呢?
后话,加了一个encoder_head_nums=8的transformer的self-attention,第一个epoch的平均准确率到了88%,全对率到了55%。很棒!self-attention也只有这样整体输入加了才有用,本质上做的是字段的hidden_layer之间的,所以之前的工作是有用的的。
之后如果觉得提高全对率更好的话,self-attention可以继续加头。觉得提高平均准确率更好的话,把loss计算方式改成每个字段分别计算返回。
现在的loss就是难学,而且目标是分对所有的。所以平均准确率比单个字段的低,整体准确率比单个字段的高是能理解的。数据少了,loss返回去难学了。就是会这样了
最印象深刻的地方总结:
整体的训练的目的就是提高全对的准确率,单个的训练目的就是提高平均的准确率。前者可能遗漏放弃,后者可能保守不前。但混合使用可能会提升效果。
一定要针对不同的任务来设计不同的训练方式,考虑loss返回的方式,!!!loss计算的是什么样的就是想要什么样的更好。。。!!!
我是真的没想到只是这样的训练方式的不同,对导致程序训练的偏向这样的不一样。以后看到更多的训练方式就能懂了
更多思路的记录
对于项目一,已经切分好的字段。
1: 可以使用推荐系统的case,给每个能分割成k长度的顾客,从总长度为m的商品列表里按顺序推荐k个。分析顾客可能是要什么商品这样的匹配模式。
在nlp里就是文本分类,不知道这个跟文本分类有什么关系。。
2: 可以试试loss分开字段分别计算返回,这样的优化就是针对平均准确率的了。中间还有一个self.attention的参数交流和一起的fc层计算。但fc层其实是没啥关系的,重点还是loss怎么计算的。
结构性和连续性问题展开
在公司这半年做的两个项目时,在分析数据错误的原因时,发现最直观的点就是特定的模型太关注结构性信息或者太关注连续性信息
Q.E.D.

Comments | 0 条评论