




脏数据处理
先用navicat连接数据库后把给的资料的excel放到mysql数据库中(这点很便利)
然后发现一些脏数据
 (因为是给其他人写代码,数据要保密所以就不展示)
(因为是给其他人写代码,数据要保密所以就不展示)
这个前面有空格,所以使用
update *tables_name* set *files_name* = trim(*files_name*);
去除前缀和后缀的空格脏数据
- LTRIM是左空格
- TRIM是左右空格
- RTRIM是右空格
之后又发现了有分号的脏数据
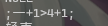
这样的就直接用
update *tables_name* set *files_name* = trim(BOTH ';' from *files_name*);
去除全部的;

这样就没有了
顺便也能去掉其他地方的;,要注意这样的处理是否与自己的代码相互拟合
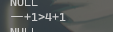
又发现音变中出现

其实是有音变,但是表示的不好
update 儿童口语词表(加拼音) set 音变 = '一+4>2+4' where 音变 = '一+4>一+4';
直接解决
(没想到脏数据处理mysql就能处理的差不多了)
对数据库中数据进行预处理
分出声变
使用python,数据库里怎么分基本都写给咱了,就处理完脏数组后放到增加了音变字Index的mysql数据库中就可以了
增加一个列
alter table *table_name* add column *file_name* varchar(255)
# alter table 是指对table的操作
# add换成drop就是删除
***
可以加:
not null 指非空
first 要在第一列
after *file_name* 要在指名列的后面
什么都不填就是在最后一列
***
下面把数据插进去
一开始出错了,表现为
insert into *table_name* *file_name* values(*value*)了
最后除了插的那行全是空值。

所以先在原先的表中创建出自增长的主键ID
alter table 儿童口语词表(加拼音) add ID int first;
alter table 儿童口语词表(加拼音) change ID ID int not null auto_increment primary key;
你们应该能看懂
然后使用update命令
update *tableName* set *fileName*=*value* where ID=*IDValue*;
一定记得在python中更新mysql时,要记得
# conn(最外层连接)
conn.commit()
再断开连接,不然更新没效果
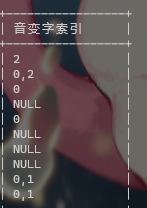
成功了,之后就备用
(标记好这是从0开始,mysql的ID是从1开始)
分出韵脚来辅助判断押韵与否
三拼音节(11个):ia ua uo uai iao ian iang uan uang iong üan
找韵脚的方法就是,只要碰到三拼音节,就将其第一个字符去掉后剩下的就是韵脚
但是突然有个问题,三拼音节里有个ü转义,数据库中没有。
第一个想法就是那就先转义
转义成功后插入表中
但是转义后发现,按照现在使用的char-featurizer分不出韵母(输入是汉字),得不到韵母
下面想出来两个方案
- 从已经分出来的转义之后的拼音和用char-featurizer判断出来的韵母共同组合判断。思考下逻辑想想怎么做
- (灵光一闪) 可以不转义,转而一碰到uan就直接判断成三拼音节。ps.在转义规则中,ü 只能由yu和u得到。 这样就完美解决。
于是就那么做了
也就做成功了
导入到table中,分出韵脚结束
撰写题目推荐算法
声母辨识题
声调辨识题
韵母辨识题
与用户可登录的网页结合
过程解决问题小记录
'in' on doubleList
doubleList = [[1,2,3],[4,5],[6]]
#对于双重数组
6 in doubleList
return: False
# in 不能查找到双重数组的最内部
[6] in doubleList
return: True
List.extend
#一个很容易不被注意的错误
[1].extend([2])
# This do nothing
#Think about why?
List.extend(*element*)只返回None
并且只有List是一个实例化的元素时才有效
[1].extend什么也留不下
temp = [1]
temp.extend([2])
然后再用temp才有效果
而且extend中,很容易出现extend(2),但其实必须是个列表,才能与另一个列表融合在一起
mysql 设置为null
直接set file_name = null就可
python去除指定字符
有三种:
- strip #只能去除首尾或单独首或单独尾
- replace #性能最差但是最方便
- re.sub #可传三个参数 第一个要替换的数据,第二个要替换成的数据,第三个是你需要改变的字符串
str = '/n1/t2/r3/n4/t5/r6/n7/t8/r9'
re.sub('[/n/t/r]','',str)
'123456789'
缺点是不能同时去除[]两个符号,因为要去除的符号要在'[]'。
# 想去除字母,也可以直接如下
result = re.sub('[a-zA-Z]',str)
对原数据库的一些特殊改变
除了要去除所有的全拼的前后的空格之外(trim()),
接下来单个记录
一:
高频词表构建时,词重复并不一样的哈希碰撞

删除表和删除表内数据
删除表:
drop table **tableName**
删除表内数据
alter table *tableName* drop column *fildName*
Q.E.D.

Comments | 0 条评论