




介绍distinct的限制
distinct作为在mysql中一个比较简介暴力的去重的方法,被高频率的使用。但是今日在使用distinct进行一个操作时,突然想到,如果distinct后面有很多字段,而有些字段相同有些字段不相同时,distinct会采用什么样的操作来去重。
经过查验后发现,distinct只有在所有一列数据所有字段全部相同时才会去重。
所以比如如果一种数据是

如果要求把vocabulary相同的就合并,万一表中有vocabulary相同但是其他的数据有其中任意一项不相同,就不能直接用distinct来“去重”了
如何检测会不会有distinct处理不了的脏数据,以及是哪个脏数据
常用的纯净的只找到
就选择那个需要作为去重(chong2)标杆的字段和count(*)取的是每一个的数量,然后将数据聚合到去重标杆字段中(约等于把每个只要是去重标杆一样的数据都聚合)然后查看聚合后数量大于1的数据。
显示出来的就是distinct处理不了的脏数据。
select a.vocabulary,count(*) from
(select distinct 儿童口语词表.vocabulary,儿童口语词表.音变字索引,儿童口语词表.声母,儿童口语词表.韵母,儿童口语词表.韵脚 from
儿童口语词表,现代汉语词典总表,义务教育词表总表 where
现代汉语词典总表.字词=儿童口语词表.vocabulary and 义务教育词表总表.分级=1)
as a group by a.vocabulary having count(*) >1;
select a.vocabulary,count(*) from (select distinct 儿童口语词表.vocabulary,儿童口语词表.音变字索引,儿童口语词表.声母,儿童口语词表.韵母,儿童口语词表.韵脚 from 儿童口语词表,现代汉语词典总表,义务教育词表总表 where 现代汉语词典总表.字词=儿童口语词表.vocabulary and 义务教育词表总表.分级=1) as a group by a.vocabulary having count(*) >1;
result:

不常用的找到并合并
或者也可以考虑
group_concat()
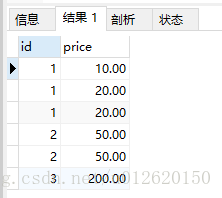
select id,group_concat(price separator ',') from goods group by id; #(默认是逗号,可以任意其他)
效果是
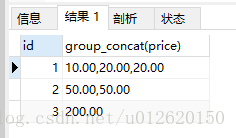
还可以在()前面加distinct,来给放到同一去重标杆相同数据去重(也要注意,一定是所有字段都一样)
以及在()后面加order by 可以排序
但是如果不是直接要这种形式的话,基本都会造成冗杂,不鲁棒和难以处理,所以主要还是第一种方法
找到了怎么修整?
题外话
在django里,我用的是
create table highfreqtable as
select vocabulary,全拼,音变字索引,声母,韵母,韵脚,音调 from
(select vocabulary,全拼,音变字索引,声母,韵母,韵脚,音调,row_number() over (partition by vocabulary,全拼) rn from
(select vocabulary,全拼,音变字索引,声母,韵母,韵脚,音调 from
儿童口语词表,现代汉语词典总表 where 儿童口语词表.vocabulary = 现代汉语词典总表.字词
union all select 组词,全拼,音变字索引,声母,韵母,韵脚,音调 from
义务教育词表总表 where 义务教育词表总表.分级=1)
as highfreq) as
temp where rn=1;
Q.E.D.

Comments | 0 条评论